Schatting van de Kansverdeling van de Significante Golfhoogte
- Hoofdstuk 1 - Inleiding
- Hoofdstuk 2 - Interpretatie en gebruik van de resultaten
- Hoofdstuk 3 - Eigenschappen van de Weibull verdeling
- Hoofdstuk 4 - Schatting van de Weibull verdeling
- Hoofdstuk 5 - Verificatie van de Schattingsmethode
- Hoofdstuk 6 - Toepassing op werkelijke gegevens
1. INLEIDING
De kansverdeling van de significante golfhoogte H wordt verondersteld overeen te komen met een Weibull verdeling. Omdat deze verdeling vooral de frequentie waarmee hogere waarden voorkomen goed voorstelt, wordt de verdeling enkel van toepassing veronderstelt boven een drempelwaarde hd die op automatische wijze uit de geobserveerde waarden wordt gekozen
De Weibull verdeling wordt beschreven door twee parameters: u is een schaalfactor en komt overeen met de waarde die met 36.8% kans wordt overschreden. k is een vormfactor en de overschrijdingskans daalt exponentieel met de kde macht van h. Figuur 1 toont enkele voorbeelden van de kansdichtheid voor u=100 en voor verschillende waarden van k. Voor k=1 is de significante golfhoogte exponentieel verdeeld. Voor lagere waarden heeft de verdeling een zwaardere staart, terwijl voor hogere waarden van k de staart korter wordt.
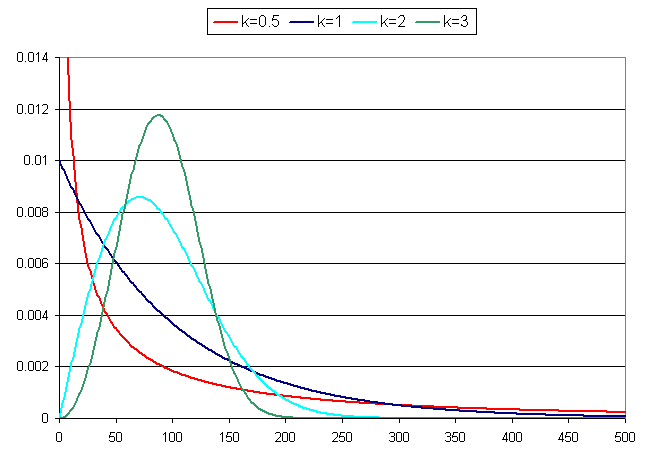
Figuur 1 : De Weibull kansdichtheid voor verschillende waarden van k en u=100
De schatting van de waarden u en k gebeurt door middel van de ML-methode ("maximum likelihood"-methode) toegepast op de geobserveerde waarden hoger dan de drempelwaarde en rekening houdend met het feit dat men het aantal waarden onder de drempelwaarde kent. Initiële schatters worden bepaald door middel van een kleinste-kwadraten benadering van de gegevens in een Weibull kwantielplot. In deze kwantielplot wordt het logarithm van de geordende waarden van de observaties (de orde-statistieken) uitgezet in functie van het logarithm van de theoretische Weibull-kwantiel die men zou vinden als k=u=1. Wanneer H effectief Weibull verdeeld is dan zou men verwachten dat deze plot goed benaderd wordt door een rechte lijn. Een voorbeeld van zulk een kwantielplot wordt getoond in Figuur 2. Dit voorbeeld betreft reële gegevens en toont dat inderdaad de Weibull verdeling enkel geldt voor de hogere waarden.
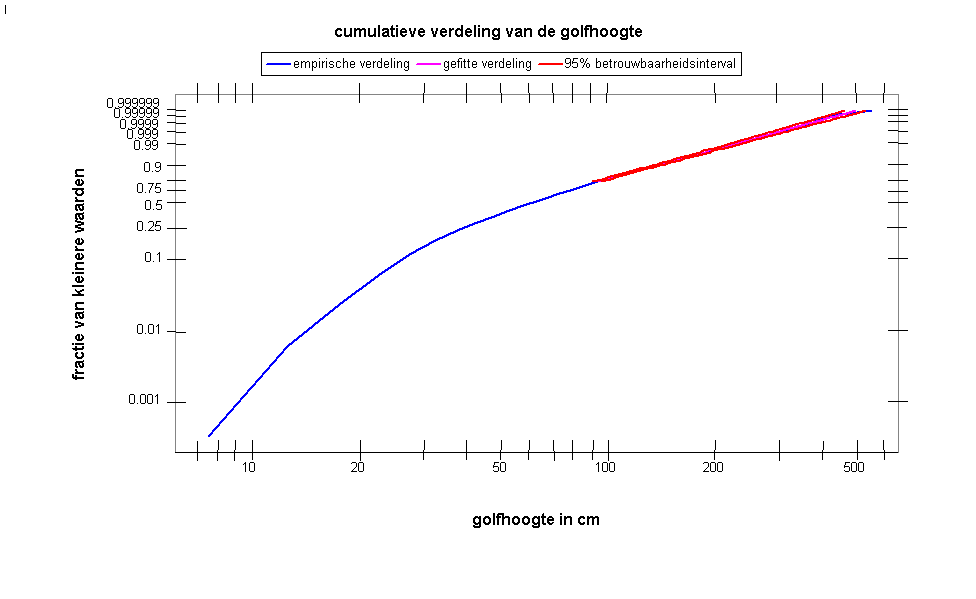
Figuur 2 : Weibull Q-Q plot
Wanneer de schattingsmethode wordt toegepast om de kansverdeling te bepalen voor een langere periode (bijvoorbeeld een jaar of een seizoen) dan dient men rekening te houden met het feit dat een over- of onderbemonstering van gegevens in bepaalde seizoenen of maanden kan leiden tot vertekende waarden (indien de kansverdeling verschilt van maand tot maand). Daarom worden aan de metingen gewichten toegekend zodat de steekproefomvang uniform is verdeeld over de verschillende seizoenen of maanden.
Om de standaardfout van de schattingen te bepalen dient men rekening te houden met de correlatie tussen opeenvolgende metingen van H. Zo kan het gebeuren dat de hogere waarden van H die het resultaat domineren worden genoteerd in één enkele storm. In dit geval is de onzekerheid op het resultaat aanzienlijk hoger dan wanneer deze waarden zouden genoteerd zijn in verschillende stormen en dus effectief onafhankelijk zijn.
Om rekening te houden met deze onzekerheid wordt de spreiding van de schatters bepaald door middel van "non-parametric blocked bootstrapping", NPB. In deze techniek wordt de schatting herhaaldelijk (B maal) toegepast op onafhankelijke lukrake selecties van tijdsblokken van de gegevens. Wanneer de gegevens gecorreleerd zijn dan is de spreiding die men noteert voor de geschatte parameters (de NPB-spreiding) groter dan de waarden die volgen uit de asymptotische formules voor een lukrake selectie van onafhankelijke gegevens (de AS-spreiding). Om tot consistente resultaten te komen, wordt daarom een equivalente (kleinere) steekproefomvang nEQ berekent zodat de AS-spreiding overeenkomt met de NPB-spreiding voor deze steekproefomvang.
Eénmaal deze steekproefomvang gekend is, is het mogelijk om een parametrische bootstrapping (PB) methode toe te passen: in dit geval worden nEQ onafhankelijke gegevens lukraak geselecteerd uit de Weibull verdeling en voor deze gegevens wordt de schattingsprocedure toegepast. De PB-methode laat toe na te gaan of de "goodness-of-fit" van de kwantielplot van de originele gegevens binnen de grenzen valt die men mag verwachten ten gevolge van toevallige fluctuaties wanneer de Weibull verdeling effectief van toepassing is. Is dit niet het geval dan wordt de drempelwaarde verhoogt om op die wijze tot een betere fit te komen.
Door herhaalde toepassing van de NPB en PB-methode wordt op deze wijze de drempelwaarde bepaald boven de welke de gefitte Weibull verdeling de gegevens goed benadert. De standaardfout van de schatters van u en k en hun correlatie wordt bepaald op basis van de PB-methode met een aangepaste steekproefomvang op basis van de NPB-spreiding. Deze standaardfouten worden ook gebruikt om (benaderende) betrouwbaarheidsintervallen op te stellen voor kwantielwaarden (waarden van H die met een bepaalde kans worden overschreden).
De procedure is toegepast op een aantal gesimuleerde resultaten om na te gaan of de correctie voor correlatie behoorlijk is en of de automatisch bepaalde drempelwaarde goed gekozen wordt. In beide gevallen werden goede resultaten genoteerd.
In dit rapport wordt de schattingsmethode en de verificatie van de schattingsmethode in detail uiteengezet. Dit gebeurt respectievelijk in Hoofdstuk 4 - Schattingsmethode en Hoofdstuk 5 - Verificatie. Ter herinnering wordt eerst in Hoofdstuk 2 - Interpretatie uiteengezet hoe men de kansverdeling van de golfhoogte kan gebruiken. Zo is het bijvoorbeeld niet evident om hieruit onmiddellijk de kans te bepalen dat een waarde H wordt overschreden in een bepaalde tijdsperiode. In Hoofdstuk 3 wordt de definitie van de Weibull verdeling herhaald. Ter afsluiting, worden in Hoofdstuk 6 enkele toepassingen op reële gegevens getoond.
Naar boven2. INTERPRETATIE EN GEBRUIK VAN DE RESULTATEN
2.1. Marginale kansverdeling
De marginale kansverdeling toont de relatieve frequentie
waarmee verschillende significante golfhoogten worden geobserveerd. In de meest gangbare voorstelling toont men
een curve die in functie van de waarde h de proportie voorstelt van de gegevens
die deze waarde h overschrijdt. Men
noemt dit een complementaire cumulatieve kansverdeling en duidt deze aan als ![]() Voor eenvoud van
notatie gebruiken we hierna echter ook p of p(h).
Voor eenvoud van
notatie gebruiken we hierna echter ook p of p(h).
De proportie p is geldig voor een oneindig lange meetreeks van gegevens op de plaats waar de kansverdeling werd bepaald en voor de tijdsperiode waarop p(h) betrekking heeft. Zo kan men spreken van een jaarlijkse, seizoensafhankelijke (lente, zomer, winter, herfst) en maandelijkse (januari, februari, ...) kansverdelingen.
Belangrijk is bovendien dat de gegevens hetzij equidistant in de tijd hetzij lukraak worden gekozen binnen de voorgestelde periode (jaar, seizoen of maand). Dit is in het bijzonder belangrijk voor de jaarlijkse en seizoensafhankelijke marginale kansverdelingen. Meestal zal p(h) immers veranderen van maand tot maand en voor een samengestelde kansverdeling (een seizoen of een jaar) wordt verondersteld dat de gegevens worden verzameld proportioneel tot de tijdsduur van de verschillende maanden.
De proportie p(h) duidt aan hoe dikwijls een bepaalde waarde h gemiddeld wordt overschreden voor een bepaald aantal waarnemingen (indien deze uniform zijn verdeeld in de tijd binnen de periode) maar geeft geen (rechtstreekse) aanduiding met welke kans een bepaalde waarde h wordt overschreden binnen een bepaalde observatieperiode.
Dit is eenvoudig te begrijpen als volgt. Stel dan men weet dat voor 10% van de H metingen een waarde van 1.5 meter overschrijdt. Voor 10,000 metingen mag men dan inderdaad stellen dat gemiddeld 1,000 metingen de waarde 1.5 meter zullen overschrijden. De eventuele variatie op dit aantal overschrijdingen en de spreiding in de tijd van de overschrijdingen is echter functie van de tijdstap tussen de verschillende metingen en de correlatie tussen de meetwaarden.
Stel bijvoorbeeld dat 100 metingen sequentieel worden uitgevoerd met een tijdstap van 1/100 seconde. Het is zeer waarschijnlijk dat dan ofwel alle gegevens de 1,5 meter zullen overschrijden ofwel niet. De kans dat de waarde 1,5 meter wordt overschreden binnen de observatieperiode van 1 seconde is in zulk geval 10%. Stel anderzijds dat de elk van de 100 metingen op een willekeurig tijdstip binnen opeenvolgende jaren worden uitgevoerd en dus een periode van 100 jaar bestrijken. In zulk geval verwacht men ieder van de metingen met een kans 10% de waarde 1,5 meter overschrijdt en het is redelijk deze kansen onafhankelijk te veronderstellen. De kans dat een bepaald aantal van deze metingen 1,5 meter overschrijdt wordt dan bepaald door middel van de binomiaalverdeling. Bijvoorbeeld de kans dat geen enkele van de metingen 1,5 meter overschrijdt is 0.9100=2.7x10-5 en dus vrijwel nihil.
Hoewel men dus weet dat gemiddeld 10% van de metingen 1,5 meter overschrijdt kan men hieruit niet rechtstreeks de kans bepalen waarmee de waarde 1,5 meter wordt overschreden binnen een bepaalde periode.
Een benaderende rekenwijze is echter mogelijk. Volgende notatie wordt hiertoe geïntroduceerd:
![]() T(h) is de gemiddelde duur waarbij de
significante golfhoogte de waarde h overstijgt;
T(h) is de gemiddelde duur waarbij de
significante golfhoogte de waarde h overstijgt;
![]() S is het tijdsinterval voor hetwelk
men de kans van overschrijdingen wenst te bepalen.
S is het tijdsinterval voor hetwelk
men de kans van overschrijdingen wenst te bepalen.
De gemiddelde totale tijdsduur tijdens dewelke de waarde h
wordt overschreden binnen S komt overeen met:
![]() (1)
(1)
Het verwachtte aantal A dat H de waarde overschrijdt bij
niet-opeenvolgende metingen is dan
![]() (2)
(2)
De gemiddelde tijd of terugkeerperiode tussen zulke
niet-opeenvolgende overschrijdingen, gemeten van het begin van 1 overschrijding
tot het begin van de volgende overschrijding is
![]() (3)
(3)
Wanneer de verwachtte tijd tussen opeenvolgende
overschrijdingen aanzienlijk groter is dan de tijd van de overschrijding en men
geen regelmaat of groepering van de overschrijdingen verwacht dan is het
redelijk om te veronderstellen dat de tijdstippen van de verschillende overschrijdingen
onafhankelijk zijn en worden beschreven door een Poisson proces. Onder die veronderstelling volgt dat de kans
dat h minstens éénmaal wordt overschreden binnen de tijdspanne S overeenkomt
met
 (4)
(4)
De eerste term in de rechterzijde verwijst naar de kans dat
de eerste waarde van de observatieperiode reeds groter is dan h. De tweede term verwijst naar de kans dat dit
niet zo is maar dat ten minste 1 overschrijding gebeurt binnen de
observatieperiode S.
Stel bijvoorbeeld dat voor 1,5 meter de gemiddelde tijdsduur van een overschrijding overeenkomt met 24 uur terwijl p(h) nog steeds overeenkomt met 10%. Voor een observatieperiode van 1 seconde is de tweede term in Vergelijking (4) te verwaarlozen en de kans van overschrijding is 10%. Voor een periode van 1 jaar is het verwachtte aantal overschrijdingen gelijk aan 36.5 en vindt men een waarde die zo goed als gelijk is aan 1.
In praktische toepassingen is de observatieperiode waarvan
sprake één of meerdere grootteordes groter dan de tijdsduur van de
overschrijding en is de kans van overschrijding p(h) bijzonder laag zodat men
binnen de observatieperiode gemiddeld minder dan één overschrijding verwacht
waar te nemen. In zulk geval wordt
Vergelijking (4) nauwkeurig benaderd door de uitdrukking:
![]() (5)
(5)
waarbij dient benadrukt te worden dat deze vergelijking
enkel een nauwkeurige benadering is wanneer
![]() (6)
(6)
Een N-jaarlijkse ontwerpwaarde komt overeen met de waarde h
waarvoor de gemiddelde tijd tussen opeenvolgende overschrijdingen overeenkomt
met N jaar. Zoals eerder aangeduid
bedraagt deze gemiddelde tijd T(h)/p(h).
Daaruit volgt dat de N jaarlijkse ontwerpwaarde hN is
gedefineerd als de waarde van h die met kans T(h)/N wordt overschreden in de
marginale kansverdeling:
![]() (7)
(7)
waarbij men T(h) in jaareenheden dient uit te drukken.
Vergelijking (7) is enkel van toepassing voor de jaarlijkse marginale kansverdeling. De aanpassing die nodig is in het geval van maandelijkse of seizoensafhankelijke kansverdelingen wordt besproken in volgende paragraaf.
De berekening van de overschrijdingskans van de golfhoogte
veronderstelt dus de kennis van de gemiddelde tijdsduur T(h). De schatting van deze tijdsduur wordt in dit
rapport niet besproken maar zal aan bod komen in een latere studie. Voor extreem hoge waarden van h is de
resolutie waarmee men de gemiddelde tijdsduur kan bepalen beperkt tot de
tijdsresolutie van de metingen: de significante golfhoogte is immers een
statistische parameter die de zeetoestand beschrijft binnen een bepaald
tijdsinterval (typisch rond de 20 minuten).
Wanneer de significante golfhoogte een bepaalde waarde éénmalig
overschrijdt dient men T(h) dan ook gelijk te stellen aan de tijdstap van de
meting. Dit verklaart meteen de
traditionele rekenwijze van de N-jaarlijkse ontwerpwaarde waarbij men de
kwantielwaarde van h gebruikt waarvoor de overschrijdingskans overeenkomt met (![]() t)/N waarbij
t)/N waarbij
![]() t het tijdsinterval voorstelt tussen opeenvolgende metingen
van H en dient uitgedrukt te worden in jaren:
t het tijdsinterval voorstelt tussen opeenvolgende metingen
van H en dient uitgedrukt te worden in jaren:
![]() (8)
(8)
Hoewel de keuze van T(h) de overschrijdingskans beïnvloedt
en dus rechtstreeks de berekening van N-jaarlijkse ontwerpwaarden voor de
significante golfhoogte wijzigt, leidt dit niet noodzakelijkerwijze tot reële
veranderingen in het ontwerp. Bij
werkelijke ontwerpberekeningen is immers niet alleen de ontwerpwaarde, maar ook
de duur van overschrijding en de gemiddelde tijd tussen opeenvolgende
golfhoogten (de "zero-crossing period") van belang. Enkel met behulp van deze gegevens kan men het aantal golven
berekenen en een verwachtte piekwaarde voor individuele golven bepalen. Een ontwerpwaarde voor de significante
golfhoogte van 2.5 meter gebaseerd op een gemiddelde overschrijdingsduur van 20
minuten is bijgevolg niet noodzakelijk ernstiger dan een ontwerpwaarde van 2
meter voor een gemiddelde overschrijdingsduur van 3 uur. In die zin kan men de keuze van T(h) tot op
zekere hoogte als een conventie beschouwen en is het gebruik van de tijdstap
die door één enkele meting wordt overschreden te verdedigen ook bij lagere
waarden van h. Wat ook de berekeningswijze moge zijn, het is in ieder geval
belangrijk om de gebruikte waarde van de overschrijdingsduur T(h) te vermelden.
Overigens is het zo dat de schatting van de
overschrijdingskans binnen een bepaalde periode beter en meer rechtstreeks kan
bepaald worden door een rechtstreekse studie van de piekwaarden van H die worden genoteerd tijdens overschrijdingen
boven een bepaald drempelniveau. Deze
waarde wordt dan representatief verondersteld voor de tijdsduur tussen
opeenvolgende metingen (![]() t). Zulk een POT
("peak-over-treshold") schatting is het onderwerp van een volgende studie.
t). Zulk een POT
("peak-over-treshold") schatting is het onderwerp van een volgende studie.
2.2. Voorwaardelijke kansverdeling
In een aantal gevallen wordt de kansverdeling van H bepaald op basis van die gegevens waarbij een andere variabele (bv. windrichting) binnen een bepaald interval valt. We noemen dit een voorwaardelijke kansverdeling. Ook de maandelijkse en seizoensafhankelijke kansverdelingen kunnen beschouwd worden als voorwaardelijke verdelingen, hoewel de selectie in dit geval op basis van het tijdstip eerder dan op basis van een andere waarneming gebeurt.
De proportie p(h) duidt nu aan hoe dikwijls een bepaalde waarde h gemiddeld wordt overschreden voor een bepaald aantal waarnemingen, indien deze uniform zijn verdeeld in de tijd binnen de periode wanneer de gestelde voorwaarde is voldaan (bv. de windrichting komt overeen met een bepaalde waarde, of het tijdstip valt in een bepaalde maand).
Net zoals voor de marginale kansverdeling is p(h) geen (rechtstreekse) aanduiding van de kans met dewelke een bepaalde waarde h wordt overschreden binnen een bepaalde observatieperiode.
Ten eerste is het, zoals eerder besproken, in principe nodig
om de gemiddelde tijdsduur van een overschrijding te bepalen tenzij men voor
extreme hoge waarden deze tijdsduur mag gelijk veronderstellen aan de tijdstap
tussen de metingen ![]() t.
t.
Ten tweede is het nodig aan te duiden hoe vaak de gestelde
voorwaarde zich voordoet binnen de totale periode S waarvoor men de kans wenst
te berekenen. We duiden deze frequentie
aan als pV. De proportie kan
rechtstreeks geschat worden op basis van de gegevens door het aantal keer dat
de voorwaarde is voldaan (nV) te delen door de totale
steekproefomvang n:
![]() (9)
(9)
In het geval van maandelijkse of seizoens-afhankelijke
kansverdelingen is de proportie pV exact gekend en komt overeen met
respectievelijk 1/12 en ¼.
Voor de bepaling van de N-jaarlijkse voorwaardelijke ontwerpwaarde dient men nu onderscheid te maken tussen volgende 2 alternatieve resultaten:
1. ofwel heeft de N-jaarlijkse ontwerpwaarde betrekking tot
kalendertijd en in dit geval gebruikt men de kwantielwaarde die overeenkomt met
T(h)/(![]() N ) waarbij men T(h) eventueel kan vervangen door
N ) waarbij men T(h) eventueel kan vervangen door
![]() t:
t:
![]() voor een
N-jaarlijke terugkeerperiode in kalendertijd
(10)
voor een
N-jaarlijke terugkeerperiode in kalendertijd
(10)
2. ofwel heeft de N-jaarlijke ontwerpwaarde betrekking tot
de reële tijd gedurende dewelke de voorwaarde is voldaan. In dit geval gebruikt men T(h)/N of (![]() t)/( N):
t)/( N):
![]() voor een N-jaarlijkse terugkeerperiode tijdens de
voorwaarde (11)
voor een N-jaarlijkse terugkeerperiode tijdens de
voorwaarde (11)
Zulke ontwerpwaarden zijn uiteraard hoger dan in voorgaande
formulering Rapportering van de ontwerpwaarden volgens kalendertijd,
zoals in Vergelijking (10), is het meest gebruikelijk omdat zulke waarden
meteen kunnen worden geassocieerd met een bepaalde overschrijdingskans binnen
één kalenderjaar (merk op dat de gestelde voorwaarde niet noodzakelijk is
voldaan). Formulering 2 is anderzijds
meer geschikt voor toepassingen waarbij men risico’s dient in te schatten en
men weet (bv. hetzij op basis van waarnemingen, hetzij op basis van
voorspellingen) dat die voorwaarde is voldaan.
Deze formuleringen is ook meer geschikt om de relatieve ernst van verschillende
voorwaarden te vergelijken.
Tenslotte dient vermeld dat het mogelijk is om
niet-voorwaardelijke N-jaarlijkse ontwerpwaarden af te leiden op basis van de
voorwaardelijke kansverdelingen wanneer die voorwaarden collectief volledig en
onderling onafhankelijk zijn (bv. alle mogelijke windrichtingen). Duiden we deze voorwaarden aan door de index
k, k=1 tot K, dan komt de samengestelde marginale kansverdeling p(h) overeen
met:
![]() (12)
(12)
waarbij pk(h) de voorwaardelijke kansverdeling
voorstelt. N-jaarlijkse ontwerpwaarden
komen dan overeen met die waarden van h waarvoor p(h)=T(h)/n. In principe dient deze ontwerpwaarde overeen
te komen met de ontwerpwaarde die wordt afgeleid op basis van de marginale
kansverdeling. Dit is echter niet
noodzakelijk het geval omwille van schattingsfouten en de inconsistentie van de
veronderstelling van de verdelingsvorm voor de voorwaardelijke kansverdelingen
en de marginale kansverdeling. De som
van verschillende Weibull verdelingen is immers niet Weibull verdeeld, tenzij
de parameters u en k dezelfde zijn.
Wanneer de voorwaardelijke verdelingen sterk verschillen, is
Vergelijking (12) in theorie een betere basis voor de berekening van de
ontwerpwaarden vermits in deze formulering rekening wordt gehouden met de
nonstationariteit van de verdelingsvorm.
In de praktijk is het echter zo dat het resultaat in Vergelijking (12)
leidt tot een grotere statistische fout omdat de deelresultaten (de
voorwaardelijke kansverdelingen) worden berekend op basis van een geringer
aantal gegevens.
2.3. Empirische frequentieverdeling en gefitte resultatten
De kansverdeling p(h) dient uiteraard te worden afgeleid op basis van de waargenomen gegevens (binnen een bepaalde periode en eventueel voor een bepaalde voorwaarde). We veronderstellen hierna dat T gegevens zijn waargenomen en duiden de overeenkomstige waarden aan als ht waarbij de index t varieert van 1 tot T.
2.3.1. Empirische frequentieverdeling
Binnen het bereik van de metingen kan de waarde p(h) rechtstreeks geschat worden door het aantal waarden ht>h te berekenen en te delen door de steekproefomvang. Omdat de golfhoogte een continue variabele is, is de kans dat H>h gelijk aan de kans dat H³h. Nochtans leidt het tellen van het aantal overschrijdingen tot een verschillend resultaat ter plaatse van de waargenomen waarden naargelang men de ene of andere definitie gebruikt. Een eenvoudige correctie hiervoor verloopt als volgt.
Duiden we de geordende waarden van h aan als h(t). h(1) is bijvoorbeeld de minimum waarde. Wanneer verschillende waarnemingen dezelfde waarde hebben (omwille van afrondingen) dan worden deze samengevoegd. Men noemt zulke waarden "ties". Het aantal metingen voor zulk een waarde wordt verder aangeduid als n(t). Voor individuele waarden is n(t)=1. Het totaal aantal orde-statistieken is niet gelijk aan T wanneer gelijke waarden in de steekproef voorkomen. Dit totaal aantal wordt daarom aangeduid door een nieuw symbool T*.
De proportie waarmee binnen de steekproef een
orde-statistiek h(t) wordt overschreden wordt dan geschat als:
 (13)
(13)
Men noemt dit ook de Blomscore van de orde-statistiek. Het gebruik van de waarde 0.5n(t)
volgt uit het feit dat 50% van de waarden waarvoor h=h(t) wordt
verondersteld groter te zijn dan h(t). Een theoretisch betere correctie kan worden voorgesteld wanneer
men de werkelijke kansverdeling p(h) kent, maar voor een voldoende grote
steekproefomvang en een gering aantal "ties" leidt dit tot vrijwel identieke
resultaten.
De empirische frequentieverdeling wordt dan bekomen door de schattingen van p(h) uit te zetten voor iedere orde-statistiek en tussen deze waarden een linear verloop te veronderstellen.
Indien men binnen de observatieperiode nonstationariteit vermoedt van de kansverdeling (bv. afhankelijkheid van maanden of seizoenen) dan is het belangrijk dat de verschillende tijdscategorieën (maanden of seizoenen) proportioneel worden bemonsterd tot de tijdsduur van deze categoriën. Indien de gegevens equidistant worden gemeten in de tijd dan is dit in principe het geval. Maar omdat tengevolge van instrumentdefecten of andere redenen de gegevens kunnen ontbreken tijdens sommige periodes is het nodig om dit na te gaan en eventueel een correctie uit te voeren. Dit gebeurt als volgt.
Veronderstellen we K verschillende tijdscategoriën met een
relatieve tijdsduur die wordt uitgedrukt door de serie waarden rk
(bv. het aantal dagen in iedere maand or seizoen). Voor iedere tijdscategorie kan nu op basis van de originele
metingen ht het aantal metingen worden bepaald. Deze worden aangeduid als fk. Om tot een uniforme verdeling van de
metingen binnen de tijdsperiode te komen wordt nu aan een meting in de
tijdscategorie k een fictief aantal metingen toegekend nt:
![]() waarbij
waarbij ![]() (14)
(14)
en k overeenkomt met de tijdscategorie van de tde
meetwaarde.
Vervolgens worden de gegevens geordend en voor de verschillende orde-statistieken worden de fictieve aantallen nt samengevoegd tot het fictief aantal n(t) waarmee de orde-statistiek werd vastgesteld.
Wanneer de
correctiefactor (rkN)/(fkR) zeer groot is dan wordt het
resultaat in sterke mate beïnvloedt door de (relatief weinige) meetwaarden in
de overeenkomstige tijdscategorie en is het eindresultaat minder
betrouwbaar. Hoewel deze vermindering
van de nauwkeurigheid in rekening wordt gebracht bij het bepalen van het
betrouwbaarheidsinterval voor de geschatte verdeling, is het zinvol de
correctiefactor te beperken tot een maximum waarde. Daarom worden eerst de correctiefactoren ck berekent
voor iedere tijdscategorie en wordt, indien nodig, deze waarde beperkt tot
3. Dan geldt:
 waarbij
waarbij ![]() (15)
(15)
en
![]() waarbij k de tijdscategorie
van de tde meting voorstelt
(16).
waarbij k de tijdscategorie
van de tde meting voorstelt
(16).
Wanneer deze beperking van toepassing is, dan is de nieuwe
totale
steekproefomvang N*=![]() kleiner dan het aantal effectief
kleiner dan het aantal effectief
waargenomen waarden. Zowel de toegepaste correctiefactoren als de
uiteindelijke afwijking ten opzichte van de vooropgestelde verdeling over de
verschillende tijdscategoriën maakt echter deel uit van het eindresultaat.
2.3.2. Gefitte kansverdeling
De empirische frequentieverdeling is een beschrijvende statistiek die, afgezien van de correctie voor de tijdscategoriën en de aanpassing van de frequenties voor de discrete natuur van de waarnemingen, de gegevens voorstelt zoals ze zijn waargenomen.
Het bereik van de empirische frequentieverdeling is bijgevolg noodzakelijkerwijze beperkt tot de minimum en maximum waargenomen waarden. Bovendien is de betrouwbaarheid van dit resultaat gering voor de schatting van p(h) bij hoge waarden vermits het aantal overschrijdingen in dit geval klein is. Hetzelfde geldt overigens bij lage waarden voor de schatting van de onderschrijdingskans, 1-p(h), die men uit dit resultaat kan afleiden.
Om tot meer betrouwbare resultaten te komen en extrapolatie mogelijk te maken is het daarom nodig om een bepaalde vorm voor de kansverdeling te veronderstellen. Voor de significante golfhoogte wordt verondersteld dat de verdeling, alleszins voor de hogere waarden, overeenkomt met een Weibull verdeling. De vorm en eigenschappen van deze verdeling worden besproken in volgend hoofdstuk. Voor het fitten van deze kansverdeling wordt uitgegaan van de orde-statistieken en de gecorrigeerde aantallen n(k) zoals hiervoor beschreven zodat de eventuele non-uniformiteit van de meetfrequentie in de tijd in rekening wordt gebracht. De veronderstelling dat de gegevens Weibull verdeeld zijn wordt verder in rekening gebracht door de empirische frequentieverdeling uit te zetten op Weibull waarschijnlijkheidspapier, ook een Weibull Q-Q plot genoemd. In deze voorstelling wordt het logarithm van de orde-statistiek uitgezet in functie van een getransformeerde Blomscore, zoals verder wordt uitgelegd in volgend hoofdstuk. Indien de gegevens Weibull verdeeld zijn, dan verwacht men een lineair verloop tussen de uitgezette waarden. Visueel kan men bijgevolg onmiddellijk nagaan in hoeverre de veronderstelling is voldaan. Bovendien bekomt men bij deze voorstelling, als het verloop inderdaad lineair is, meer nauwkeurige resultaten bij de interpolatie van de empirische frequentieverdeling.
3. EIGENSCHAPPEN VAN DE WEIBULL VERDELING
3.1. Vorm van de verdeling
De significante golfhoogte H wordt Weibull verdeeld
verondersteld boven een drempelwaarde hd.De complementaire cumulatieve kansverdeling wordt dan beschreven
als:
 (17)
(17)
waarbij u en k twee parameters voorstellen.u is een schaalfactor en komt overeen met de
significante golfhoogte die in 37% van de gevallen wordt overschreden. k is een vormfactor die de zwaarte van de
staart bepaald.Voor het bijzondere geval
k=1, vindt men de exponentiele verdeling.Naarmate k verhoogt verlaagt de frequentie waarmee extreem hoge waarden
voorkomen.
De overeenkomstige kansdichtheid is van de vorm:
 (18)
(18)
Enkele voorbeelden van de vorm van de
kansdichtheid worden voorgesteld in Figuur 1.
3.2. Weibull Q-Q plot
Noemen we hp de p-bovenkwantielwaarde (d.w.z. de
waarde die met kans p wordt overschreden) dan volgt uit (17) dat:
![]() (19)
(19)
of
![]() (20)
(20)
-log(p) komt overeen met de p-bovenkwantielwaarde van een
Weibull verdeling waarvoor u=1 en k=1.
Deze kwantielwaarde noemen we de standaard-Weibull bovenkwantiel. Vergelijking (20) toont dat het logarithm
van de kwantielwaarden voor een Weibull verdeling met ongekende parameters u en
k linear varieert in functie van het logarithm van de standaard-Weibull
bovenkwantielen. Het intercept van deze
lijn komt overeen met log(u), terwijl 1/k de helling bepaalt.
Stel nu dat op basis van een meetreeks de orde-statistieken
h(t) zijn gekend voor t=1,T*.
Het aantal waarnemingen h(t) in de meetreeks is n(t)
en de overeenkomstige empirische schatting van de overschrijdingsfrequentie
wordt aangeduid als ![]() .
Wanneer men het logarithm van de orde-statistieken log(h(t))
uitzet in functie van het logarithm van de standaard-Weibull bovenkwantielen
voor de verschillende schattingen
.
Wanneer men het logarithm van de orde-statistieken log(h(t))
uitzet in functie van het logarithm van de standaard-Weibull bovenkwantielen
voor de verschillende schattingen ![]() dan verwacht men een
linear verloop boven de drempelwaarde hd.Zulk een grafiek noemt men
een Weibull Q-Q plot (zie Figuur 2 voor
een voorbeeld). Vermits het intercept
en de helling van het linear verloop bepaalt wordt door de parameters u en k,
kan men op basis van deze grafiek ook de waarde van u en k schatten zoals
verder wordt uiteengezet in volgend hoofdstuk.
dan verwacht men een
linear verloop boven de drempelwaarde hd.Zulk een grafiek noemt men
een Weibull Q-Q plot (zie Figuur 2 voor
een voorbeeld). Vermits het intercept
en de helling van het linear verloop bepaalt wordt door de parameters u en k,
kan men op basis van deze grafiek ook de waarde van u en k schatten zoals
verder wordt uiteengezet in volgend hoofdstuk.
4. SCHATTING VAN DE WEIBULL VERDELING
4.1. Algemene beschrijving van de procedure
De schattingsprocedure die hier wordt uiteengezet is van toepassing op een meetreeks van h waarden, waarbij voor iedere waarde h de overeenkomstige tijdscategorie k is aangeduid. Het relatieve aantal metingen dat men in elke tijdscategorie verwacht is eveneens gekend en wordt aangeduid door rk.
In Paragraaf 2.3 is reeds uiteengezet hoe men op basis van zulke gegevens de orde-statistieken h(t), t=1,T* en de overeenkomstige gecorrigeerde aantallen n(t) kan bepalen. Ter herinnering: de correctie zorgt ervoor dat de bemonstering van de h waarden uniform is in de tijd en dus geen vertekend resultaat oplevert indien een deelperiode over- of onderbemonsterd is. In de procedure wordt tevens gebruik gemaakt van de geschatte empirische overschrijdingskans, die wordt aangeduid als p(t).
De originele meetreeks wordt tevens onderverdeeld in consecutieve tijdsblokken van 1 maand. In tegenstelling tot de tijdscategoriën behoren gegevens gemeten in dezelfde maand maar in verschillende jaren tot verschillende tijdsblokken. Het totaal aantal tijdsblokken wordt hierna genoteerd als M. Deze onderverdeling wordt gebruikt om lukraak de M tijdsblokken van de gegevens te herbemonsteren in de niet-parametrische bootstrapping. Door tijdsblokken te herbemonsteren eerder dan individuele gegevens behoudt men de correlatiestructuur in de aldus gesimuleerde tijdreeks. Deze correlatie kan de spreiding van de schatters sterk beïnvloeden: een sterke positieve correlatie tussen opeenvolgende gegevens vermindert de effectieve steekproefomvang van onafhankelijke gegevens die beschikbaar zijn om de schatters te bepalen.
De schattingsprocedure omvat een iteratie om de drempelwaarde te bepalen waarboven de Weibull verdeling de empirische verdeling goed benadert.
De volledige procedure omvat dan volgende stappen (zie schema):
1. de drempelwaarde hd wordt initiëel gelijk veronderstelt aan 0;
2. orde-statistieken en de overeenkomstige gecorrigeerde aantallen worden bepaald op basis van de meetreeks;
3. de waarde van u en k wordt geschat voor de gekozen drempelwaarde. Bij deze stap worden enkel waarden boven de drempelwaarde gebruikt. Het totaal aantal waarnemingen dat gelijk is of kleiner dan de drempelwaarde wordt eveneens in rekening gebracht. Deze stap omvat volgende deelberekeningen:
a. schatting van de kleinste-kwadraten schatters ("least-squares" of LS-schatters) van u en k op basis van de Weibull Q-Q plot;
b. iteratie om de ML-schatters (waarden die de L-funktie maximaliseren) van u en k te berekenen. Startwaarden bij de iteratie komen overeen met de LS-schatters;
c. berekening van een "goodness-of-fit" statistiek of G-statistiek. De G-statistiek die gebruikt wordt in deze procedure komt overeen met de correlatie tussen de gefitte bovenkwantielen voor de verschillende orde-statistieken en de waargenomen orde-statistieken.
niet-parametrische schatting van de spreiding van de
schatters: uit de M tijdsblokken worden M tijdsblokken lukraak geselecteerd met
teruglegging en stappen 1 tot 3 worden herhaald. Deze selectie wordt B maal uitgevoerd en voor de B schattingen
van u en k wordt de standaarddeviatie bepaald van de schattingen: ![]() en
en
![]() ;
;
door vergelijking van de eerder bekomen
standaarddeviaties hetzij (bij de eerste iteratie van deze stappen) met de
assymptotische standaarddeviaties van de schatters, ![]() en
en
![]() , hetzij (bij de volgende iteraties) met de
standaarddeviaties van de schatters bepaald door parametrische bootstrapping in
de vorige iteratie,
, hetzij (bij de volgende iteraties) met de
standaarddeviaties van de schatters bepaald door parametrische bootstrapping in
de vorige iteratie, ![]() (Neq) en
(Neq) en
![]() (Neq), wordt een nieuwe equivalente
steekproefomvang Neq bepaald;
(Neq), wordt een nieuwe equivalente
steekproefomvang Neq bepaald;
parametrische schatting van de spreiding van de
schatters gebruikmakend van de benaderende equivalente steekproefomvang: in
deze stap worden Neq onafhankelijke gegevens gesimuleerd uit de geschatte
Weibull verdeling. Deze simulatie wordt
B maal uitgevoerd en op basis van de B schattingen wordt de standaarddeviatie
bepaald van de schattingen: ![]() en
en
![]() ;
;
de equivalente steekproefomvang wordt herberekend om een betere overeenkomst te maken tussen de niet-parametrische en de parametrische schatting van de standaarddeviaties;
herhaling van de parametrische schatting van de
spreiding van de schatters, ditmaal gebruikmakend van de verbeterde equivalente
steekproefomvang. Naast de
standaarddeviaties van de schattingen wordt ook het gemiddelde en de
standaarddeviatie van de G-statistiek bepaald: ![]() en
en
![]() ;
;
beoordeling van de G-statistiek en keuze van een volgende drempelwaarde: in deze stap wordt nagegaan of de fit voldoet en indien niet dan wordt de iteratie verder gezet bij stap 2 met een nieuwe hd waarde;
wanneer de drempelwaarde is bepaald waarbij de fit voldoet (of zo goed mogelijk is) dan wordt de parametrische bootstrapping B’ maal herhaald om meer nauwkeurige resultaten af te leiden. Uiteindelijke resultaten betreffende de spreiding van de schattingen en de G-statistiek zijn gebaseerd op de B+B’ simulaties. Naast de standaarddeviaties van de schattingen u en k worden ook benaderende betrouwbaarheidsintervallen berekend voor de gefitte kwantielwaarden die overeenkomen met de overschrijdingskansen p(t).
In de volgende paragrafen worden de rekenmethodes die gebruikt worden in deze stappen verder toegelicht. Meer bepaald:
1. de berekening van LS-schatters van u en k;
2. de berekening van ML-schatters van u en k;
3. de berekening van de G-statistiek;
4. uitvoeren van de niet-parametrische bootstrapping;
5. uitvoeren van de parametrische bootstrap;
6. berekening van de equivalente steekproefomvang;
7. beoordeling van de G-statistiek en keuze van de drempelwaarde;
8. berekening van betrouwbaarheidsintervallen voor de kwantielwaarden van H.
In een laatste paragraaf wordt toegelicht hoe de gemeten waarden, indien nodig, dienen afgerond te worden.
4.2. Berekening van ls-schatters van U en K
LS-schatters van u en k worden bepaald op basis van Vergelijking (20) waarbij hp wordt vervangen door de orde-statistieken h(t) en p wordt vervangen door p(t) voor alle h(t) die groter zijn dan of gelijk aan hd. Voor de schatting wordt een gewogen kleinste-kwadraten techniek gebruikt: het gewicht voor ieder punt h(t) wordt gelijkgesteld aan het aantal waarnemingen n(t), behalve voor de drempelwaarde hd waar het gewicht wordt gelijkgesteld aan het aantal waarnemingen dat kleiner is dan of gelijk aan de drempelwaarde.
4.3. Berekening van ML-schatters van U en K
De L-funktie ("Likelihood"-functie) van de gegevens boven de
drempelwaarde hd komt overeen met:
 (21)
(21)
waarbij nd overeenkomt met het aantal waarden dat
kleiner of gelijk is aan de drempelwaarde en td de orde aanduidt van
de statistiek die kleiner of gelijk is aan de drempelwaarde.
Het zoeken naar de waarden van u en k die de L-funktie maximaliseren (de ML-schatters) gebeurt door middel van een dubbele iteratie. Voor gegeven k is het mogelijk om iteratief de overeenkomstige schatter van u te berekenen en voor deze waarde de correctie te berekenen die aan k moet worden toegebracht. Rekening houdend met de waarde en het teken van deze correctie wordt dan een nieuwe k-waarde bepaald en de schatting van u herhaald tot de correctie voor k voldoende klein is. Initiële waarden voor de schatters worden gelijkgesteld aan de LS-schatters.
Verdere details betreffende de ML-schatters worden uiteengezet in Appendix A.
4.4. Berekening van de G-statistiek
De G-statistiek dient een maat te zijn in hoeverre de gefitte Weibull verdeling de oorspronkelijke empirische frequentieverdeling benaderd bij en boven de drempelwaarde. Vermits fouten op de werkelijk voorspelde waarden eerder dan op de logarithmisch getransformeerde variabelen van belang zijn in de praktijk werd in de schattingsprocedure gekozen voor een statistiek die het verschil tussen de werkelijke en gefitte orde-statistieken samenvat.
Bij een perfecte fit zijn de gefitte kwantielwaarden q(t) die men vindt voor de overschrijdingskansen p(t) identiek aan de orde-statistieken h(t). De correlatie tussen q(t) en h(t) is bijgevolg een directe maatstaf voor de "goodness-of-fit". Deze correlatie wordt berekend rekening houdend met het aantal waarnemingen dat tot elke orde-statistiek behoort als volgt:
 (22)
(22)
waarbij
![]() en
en
![]() overeenkomen met het
gewogen gemiddelde van de waarden gelijk aan of groter dan
overeenkomen met het
gewogen gemiddelde van de waarden gelijk aan of groter dan
![]() :
:
 (23)
(23)
 (24)
(24)
Voorgaande formulering is van toepassing voor een rechte
lijn waarvan het intercept niet gekend is.
In dit geval verwacht men echter dat het intercept nul is en de lijn
door de oorsprong gaat. Om dit in
rekening te brengen wordt in Vergelijking (22) de gemiddelde waarden
![]() en
en
![]() gelijkgesteld aan 0,
eerder dan bepaald op basis van voorgaande vergelijking. Het praktisch effect van deze aanpassing is dat
de "goodness-of-fit" bij hogere waarden relatief gezien een grotere invloed
hebben op de G-statistiek, hetgeen wenselijk is.
gelijkgesteld aan 0,
eerder dan bepaald op basis van voorgaande vergelijking. Het praktisch effect van deze aanpassing is dat
de "goodness-of-fit" bij hogere waarden relatief gezien een grotere invloed
hebben op de G-statistiek, hetgeen wenselijk is.
Omwille van de beperkte steekproefomvang verwacht men niet
dat deze correlatie effectief gelijk is aan 1.
Om de correlatie te beoordelen is het daarom nodig de gemiddelde waarde
en de standaarddeviatie te kennen voor de statistiek indien de gegevens
effectief Weibull verdeeld zijn. Dit
gebeurt in de procedure door de G-statistiek te herrekenen voor de gesimuleerde
waarden in de parametrische bootstrap.
De correlatie is echter beperkt tot 1 en voor hoge waarden en een kleine
steekproefomvang zeker niet normaal verdeeld.
Om een normale verdeling beter te benaderen wordt de G-statistiek daarom
gelijkgesteld aan de volgende getransformeerde variabele:
![]() (25)
(25)
Het is deze G-statistiek die wordt berekend voor de fit van
de oorspronkelijke gegevens en die herhaaldelijk wordt berekend bij het
toepassen van de parametrische bootstrap. Noemen we voor deze laatste simulaties
mG
de gemiddelde waarde en
sG
de standaardeviatie dan kan men volgende Z-statistiek berekenen die onder de
null-hypothese dat de gegevens effectief Weibull verdeeld zijn benaderend
standaard normaal verdeeld is:
![]() (26)
(26)
De kans dat de data effectief Weibull verdeeld zijn en de
G-statistiek kleiner zou zijn dan de g-waarde berekend voor de oorspronkelijke
gegevens noemt men de P-waarde van de test-statistiek. Deze P-waarde is de kans dat men voor een
standaardnormaal verdeelde toevalsvariabele een waarde kleiner dan Z vindt.
Hoe de voorgaande statistieken worden gebruikt om de drempelwaarde te kiezen wordt uiteengezet in Paragraaf 4.7.
4.5. Niet-parametrische bootstrap
Bij de niet-parametrische bootstrap worden uit de steekproef van M tijdsblokken lukraak M tijdsblokken gekozen met teruglegging. In de nieuwe tijdreeks zullen sommige tijdsblokken bijgevolg meermaals voorkomen terwijl andere niet worden gekozen.
Om de statistieken die volgen uit de niet-parametrische bootstrap voldoende nauwkeurig te berekenen is het nodig deze bootstrap meermaals uit te voeren (B maal). Men heeft aangetoond dat de nauwkeurigheid verbetert indien in de globale keuze van de MxB tijdsblokken ieder tijdsblok M maal voorkomt. Men verwijst naar deze selectietechniek als "balanced bootstrapping" en het is deze techniek die is toegepast in de schattingsprocedure. De praktische uitvoering van de selectie gebeurt door B lukrake selecties zonder teruglegging van M blokken uit een vector van MxB blokken waarin ieder block M maal voorkomt.
4.6. Parametrische bootstrapping
In tegenstelling tot de non-parametrische bootstrap waar de gesimuleerde tijdreeksen uit de oorspronkelijke gegevens worden gekozen en de gegevens dus niet noodzakelijkerwijze Weibull verdeeld zijn en onafhankelijk, wordt in de parametrische bootstrap N onafhankelijke gegevens gesimuleerd uit de geschatte Weibull verdeling.
Omdat enkel de waarden boven de drempelwaarde dienen gekend
te zijn, wordt eerst de waarde van
nd
(het aantal waarden kleiner of
gelijk aan
hd
) gesimuleerd.
Nd
is binomiaal verdeeld met parameters N (het aantal
experimenten) en
![]() (27)
(27)
Wanneer p dN en (1-p d)N groter zijn dan
10 mag men de verdeling van N
d
benaderen door een normaalverdeling
met verwachtingswaarde p dN en variantie (1-p d)p
dN. Wanneer deze voorwaarde vervuld is wordt n
d
gesimuleerd als:
![]() (28)
(28)
waarbij overeenkomt met de
inverse standaardnormaal verdeling en U een gesimuleerde toevalsvariabele
voorstelt met uniforme verdeling binnen het interval (0,1). De N-n d
overige waarden worden dan gesimuleerd door herhaalde toepassing van volgende
vergelijking:
![]() (29)
(29)
waarbij U opnieuw overeenkomt met een toevalsvariabele met
uniforme verdeling binnen het interval (0,1).
Indien p dN of (1-p d)N kleiner zijn
zijn dan 10 dan wordt de simulatie rechtstreeks uitgevoerd voor alle N gegevens
als volgt:
 (30)
(30)
4.7. Berekening v/d equivalente steekproefomvang
De bedoeling van de equivalente steekproefomvang Neq
is dat de standaarddeviaties van de schattingen bij de parametrische bootstrap
benaderend overeenkomt met de waarden die worden gevonden op basis van de
niet-parametrische bootstrap.Verschillen tussen de twee resultaten bij een zelfde steekproefomvang
zijn te wijten aan het feit dat bij de parametrische bootstrap de gesimuleerde
gegevens effectief Weibull verdeeld zijn en onafhankelijk, terwijl bij de
niet-parametrische bootstrap de gegevens worden gekozen uit de originele
tijdreeks en bijgevolg niet noodzakelijkerwijze onafhankelijk of Weibull
verdeeld zijn.Een andere ongewenste
reden voor eventuele verschillen is dat beide bootstrap methodes slechts een
beperkt aantal keer (B maal) wordt uitgevoerd en de geschatte
standaarddeviaties bijgevolg niet exact zijn.
Voor de ML-methode toegepast op niet-gecensureerde gegevens
(dat wil zeggen voor een drempelwaarde gelijk aan 0) beschikt men over volgende
asymptotische formules voor de varianties van u en k die geldig zijn bij grote
steekproefomvang:
![]() (31)
(31)
![]() (32)
(32)
Voor de drempelwaarde 0 kan de equivalente steekproefomvang
bijgevolg berekend worden als:
 (33)
(33)
Zoals eerder vermeld is omwille van het beperkt aantal
bootstraps B dat wordt uitgevoerd de schatting van de NPB-spreiding van u en k
onzeker. Om te voorkomen dat door
toevallige variatie de steekproefomvang wordt veranderd, wordt daarom de
benedengrens gebruikt van een 90% eenzijdig betrouwbaarheidsinterval. Voor een variantie s2 bepaald op basis van
B gegevens komt deze benedengrens overeen met:
![]() (34)
(34)
waarbij ![]() overeenkomt met de 10% bovenkwantiel van een chi-kwadraat
overeenkomt met de 10% bovenkwantiel van een chi-kwadraat
verdeelde toevalsvariabele met N-1
vrijheidsgraden.
In Vergelijking (23) worden de NPB-schattingen van de
standaarddeviaties van u en k beide gelijkgesteld aan de minimum waarden
berekend op basis van Vergelijking (34).
Uiteraard wordt de equivalente steekproefomvang verder beperkt tot de
oorspronkelijke steekproefomvang N, zodat
 (35)
(35)
De asymptotische formules houden echter geen rekening met
het feit dat gegevens kleiner of gelijk aan de drempelwaarde worden
gecensureerd en de formules zijn enkel geldig voor voldoende grote
steekproefomvang. Daarom wordt een
verbeterde berekening uitgevoerd van de equivalente steekproefomvang door
rechtstreeks de spreiding te vergelijken van de parametrische en niet-parametrische
bootstrap en te veronderstellen dat de variantie van de schatters inverse
proportioneel is tot de steekproefomvang.
Dit leidt tot volgende gecorrigeerde steekproefomvang:
![]() (36)
(36)
waarbij voor u:
 (37)
(37)
en voor k:
 (38)
(38)
Bij het gebruik van voorgaande formules dient men nu echter
rekening te houden zowel met de onzekerheid op de schatting van de
NPB-spreiding als die van de PB-spreiding.
Om toevallige reducties van de steekproefomvang te vermijden wordt
daarom de bovengrens gebruikt van een 90% éénzijdig betrouwbaarheidsinterval. Deze waarde komt overeen met de 10%
bovenkwantielwaarde van een F-verdeling met BNPB-1 en
B
PB-1
vrijheidsgraden:
![]() (39)
(39)
BNPB en BPB komen overeen met het
respectieve aantal simulaties uitgevoerd bij de niet-parametrische en parametrische bootstrap.
-
De uiteindelijke gecorrigeerde steekproefomvang wordt dan gelijkgesteld aan het minimum van beide resultaten en begrensd door de oorspronkelijke steekproefomvang:
 (40)
(40)
Wanneer de drempelwaarde niet nul is dan zijn de assymptotische formules niet van toepassing. Daarom wordt voor het bepalen van de equivalente steekproefomvang ook in dit geval Vergelijking (40) toegepast, waarbij N eq in Vergelijking (36) overeenkomt met de gecorrigeerde equivalente steekproefomvang die werd berekend bij de voorgaande drempelwaarde. Deze berekening levert een betere benadering op, vermits de drempelwaarde naar de uiteindelijke drempelwaarde convergeert.
4.8. Beoordeling van de G-statistiek en keuze van de drempelwaarde.
Zoals eerder uiteengezet in Paragraaf 4.3 kan men door middel van het resultaat van de parametrische bootstrap de P-waarde van de G-statistiek bepalen.
Bovendien wordt voor de drempelwaarde van toepassing de
MSE-fout ("mean-square error) van de G-statistiek berekend:
 (41)
(41)
Wanneer de G-statistiek groter is dan gemiddeld wordt
verwacht, dan wordt enkel de variantie van de G-statistiek in rekening
gebracht; is dit niet zo dan wordt ook de kwadratische vertekening ten opzichte
van deze waarde toegevoegd. De MSE
waarde vermindert naarmate G dichter bij de verwachtingswaarde ligt maar
vemeerdert wanneer de variantie stijgt zodat het gebruik van een kleinere
steekproefomvang wordt gepenalizeerd.
Indien bij de drempelwaarde van 0 de P-waarde groter is dan 5% dan wordt deze fit als voldoende beschouwd. Is dit niet het geval, dan wordt de minimum drempelwaarde gelijkgesteld aan 0 en de bijhorende P- en MSE-waarden worden genoteerd. We noemen deze waarden hmin, Pmin, MSEmin.De maximum waarde van de drempel hmax wordt aangeduid als onbepaald. Vervolgens wordt de nieuwe drempelwaarde gelijkgesteld aan de mediaan van de steekproefgegevens (de waarde die met frequentie 50% wordt overstegen) en volgend iteratieschema wordt toegepast:
Indien de P-waarde voor de nieuwe drempelwaarde groter is dan 50% dan wordt deze waarde als maximum waarde voor de drempel genoteerd.
Is de P-waarde kleiner dan 50% dan wordt nagegaan of de P-waarde groter is dan 5%. Wanneer deze voorwaarde is voldaan en indien Pmin nog steeds lager is dan 5% dan vervangt de nieuwe drempelwaarde de minimum waarde hmin en de overeenkomstige statistieken worden aangepast (Pmin en MSEmin).
Is de P-waarde kleiner dan 5% of is de P-waarde bij het minimum reeds groter dan 5% dan wordt nagegaan of de MSE-waarde kleiner is dan de MSE-waarde bij het drempelminimum. Is dit zo, dan wordt het drempelminimum vervangen door de huidige drempelwaarde. Is dit niet zo, dan wordt het drempelmaximum vervangen door de huidige drempelwaarde.
De keuze van de volgende drempelwaarde wijzigt zich naargelang een maximum drempelwaarde al dan niet reeds is bepaald.
Wanneer hmax is gekend dan wordt de nieuwe drempelwaarde gelijkgesteld aan het gemiddelde van de minimum en maximum waarde. De iteratie wordt stopgezet indien het verschil tussen het aantal steekproefgegevens dat de minimum en maximum drempelwaarde overstijgt kleiner is dan 5% van de steekproefgegevens of wanneer het verschil tussen de minimum en maximum drempelwaarde overeenkomt met de nauwkeurigheid van de h-metingen.
Is hmax niet gekend dan wordt de nieuwe drempelwaarde gelijkgesteld aan de mediaan van de steekproefgegevens die de huidige drempelwaarde overstijgen. Indien dit aantal kleiner is dan 50 dan wordt de iteratie stopgezet.
Voorgaand algoritme convergeert in principe naar de drempelwaarde waarbij de MSE-waarde van de G-statistiek minimaal is terwijl de P-waarde 5% overstijgt. Omdat de P- en MSE-waarde berekend worden met slechts een beperkte nauwkeurigheid is het echter mogelijk dat minder optimale drempelwaarden worden gekozen. Bovendien dient men volgende twee uitzonderingen te noteren: wanneer de P-waarde groter is 5% bij de drempelwaarde 0 dan wordt geen censoring toegepast; indien geen P-waarde wordt bereikt die hoger is dan 5% bij censoring voor opeenvolgende mediaanwaarden (50%, 25%, 12.5% , 6.25%, ...) dan wordt het drempelniveau gelijkgesteld aan de hoogste van die reeks mediaanwaarden waarbij meer dan 50 steekproefgegevens de waarde overschrijden.
Om toevallige fluctuaties zoveel mogelijk uit te sluiten wordt de niet-parametrische bootstrapping simulatie enkel toegepast bij de drempelwaarde 0 en wordt bij de daaropvolgende simulaties dezelfde tijdsblokken gebruikt. Deze afhankelijkheid tussen de gesimuleerde resultaten bij verschillende drempelwaarden verbetert de relatieve nauwkeurigheid van de variatie van de NPB-spreiding van de schatters, terwijl de nauwkeurigheid bij 1 enkele drempelwaarde dezelfde blijft. Bovendien wordt door deze operatie de schattingsprocedure aanzienlijk versnelt. Voor de parametrische bootstrap is een gelijkaardige operatie niet mogelijk omdat de equivalente steekproefomvang varieert naargelang de drempelwaarde en het aantal te simuleren waarden varieert.
4.9. Berekening van betrouwbaarheidsintervallen voor de kwantielwaarden van H
Om de nauwkeurigheid van de resultaten te verbeteren wordt, éénmaal de optimale drempelwaarde is bereikt, de parametrische bootstrap methode nogmaals B’ keer toegepast. Statistieken betreffende de spreiding van de eindresultaten zijn gebaseerd op deze simulaties samengevoegd met de simulaties in de laatste iteratiestap. Voor eenvoud van de notatie wordt het totaal bootstrap simulaties verder opnieuw aangeduid als B.
De B schattingen van u en k laten toe om de spreiding en de
correlatie van de schatters te bepalen. Vergelijking (20) toont dat het
logarithm van de gefitte kwantielwaarden linear verloopt met de waarden van log(u)
en 1/k. Daarom worden ook de varianties
van deze getransformeerde schatters en hun covariantie bepaald op basis van de
gesimuleerde resultaten. Voor een
gegeven p waarde wordt de standaarddeviatie van het logarithm dan berekend als
 (42)
(42)
Een benaderend 95% tweezijdig
betrouwbaarheidsinterval voor de schatting van hp komt dan overeen
met:
![]() (43)
(43)
waarbij hp de ML-schatting voorstelt.
4.10. Afronding van de meetwaarden
Om het aantal gegevens te beperken is het nuttig om de oorspronkelijke meetgegevens af te ronden en dus te discretiseren. Noemen we Dh de stap tussen opeenvolgende metingen (bv. 5 cm). Voor de juiste toepassing van voorgaand algoritme dient men volgende punten te noteren.
Omdat de empirische kans van overschrijding wordt geschat er vanuitgaande dat 50% van de gegevens boven de genoteerde waarde liggen dient men voor een gegeven h-waarde de dichtsbijzijnde waarde noteren. Om te vermijden dat frequenties worden genoteerd bij de 0-waarde, dient men daarom de h-waarden te groeperen in intervallen (0, Dh], (Dh, 2Dh], ... en voor ieder interval de gemiddelde waarde te noteren. De orde-statistieken zijn bijgevolg van de vorm 0.5Dh, 1.5Dh, ...
Voor de drempelwaarde hd wordt anderzijds in de schattingsprocedure een schatting gemaakt van de kans dat deze waarde wordt onderschreden door alle aantallen voor h-waarden kleiner dan de drempel op te tellen. Door de drempelwaarden steeds gelijk te stellen aan veelvouden van Dh, is dit een juiste schatting.
5. VERIFICATIE VAN DE SCHATTINGSMETHODE.
Om de schattingsmethode te verifieren werd de methode toegepast of 200 gesimuleerde steekproeven elk met 1500 datapunten. Volgende 3 gevallen worden beschouwd:
1. de gegevens zijn lukraak en onafhankelijk gekozen uit een Weibull verdeling waarvoor u=60 en k=1.15. De bedoeling is na te gaan of de schattingsprocedure de juiste waarde van u en k vindt en of de geschatte spreiding overeenkomt met de spreiding van de schatters;
2. zoals in 1. maar in dit geval worden slechts 300 datapunten gesimuleerd en elk punt wordt 5 maal gedupliceerd. De bedoeling is na te gaan of de schattingsmethode deze extreme vorm van correlatie juist kan detecteren;
3. zoals in 1. maar waarden kleiner dan 80 worden vervangen door een toevalsvariabele waarvan de kansdichtheid overeenkomt met een lognormale verdeling met mediaanwaarde 40 en standaarddeviatie van het logarithm gelijk aan 1 die wordt afgeknot tussen de waarden 20 en 80. De gemengde verdeling die hieruit volgt wordt getoond in Figuur 3. De bedoeling is na te gaan of de schattingsprocedure de drempelwaarde van 80 goed detecteert en tot correcte schattingen van u en k leidt.
5.1. Gesimuleerde WEIBULL verdeling
Resultaten van deze simulatie worden getoond in Appendix B en worden hier overlopen aan de hand van de samenvattende statistieken:
Het aantal meetpunten is 1500. In ongeveer 90% van de gevallen wordt geen correlatie gevonden en blijft de steekproefomvang dezelfde (zie Plot NEQV ). Wanneer de steekproefomvang wordt verminderd is dit eerder beperkt, zoals men zou verwachten.
Slechts in enkele gevallen (ongeveer 3%, zie plots FCEN en HTRE) wordt een drempelwaarde hoger dan 0 geschat. Wanneer dit echter gebeurt, dan is het mogelijk dat een redelijk hoge drempelwaarde wordt aangenomen. Vermoedelijk gebeurt dit voor gesimuleerde steekproeven waarbij de hoogste orde-statistieken toevallig sterk afwijken van de theoretische waarden en in dit geval zal het algoritme trachten om deze hoge waarden beter te benaderen. Anderzijds wordt natuurlijk in zulke gevallen een grotere standaardfout berekend voor de schattingen.
De resultaten voor de schattingen u en k tonen dat deze goed overeenkomen met de voorspelde asymptotische waarden. Waarden MLU0 en MLK0 verwijzen naar de schattingen zonder aanpassing van de steekproefomvang en voor drempelwaarde 0. EMLU en EMLK verwijzen naar de uiteindelijke schattingen. De gemiddelde waarden komen goed overeen en benaderen zeer goed de werkelijke waarden, u=60 en k=1.15. Omdat het algoritme eventueel de steekproefomvang vermindert en/of de drempelwaarde verhoogt worden wel iets hogere standaarddeviaties genoteerd. Zoals in de volgende paragrafen wordt getoond wordt deze lichte verhoging echter meer dan gecompenseerd door de kleinere vertekening in de schatting van de juiste waarden en hun standaardfout wanneer correlatie en/of een drempelwaarde werkelijk voorkomt.
SMLU en SMLK is de geschatte standaardfout van de schattingen. Gemiddeld komen deze waarden goed overeen met de asymptotische waarden. Plot SMLK en SMLU tonen echter dat in enkele gevallen relatief hoge waarden worden geschat. Dit gebeurt voor die gevallen waarbij de drempelwaarde wordt verhoogd of de steekproefomvang wordt verminderd.
Ter vergelijking worden SMLU0 en SMLK0, de geschatte standaardfouten voor drempelwaarde 0 en zonder vermindering van de steekproefomvang, getoond. Deze waarden tonen een merkelijk lagere spreiding en benaderen gemiddeld ook zeer juist de asymptotische waarden. De spreiding op deze resultaten is uiteraard niet gewenst en zou verder kunnen verminderd worden door het opvoeren van het aantal bootstrap. De relatieve standaardfout is echter slechts een 10% bij het gebruikte bootstrap aantal hetgeen een redelijke nauwkeurigheid is.
De correlatie tussen u en k komt overeen met de waarde die theoretisch wordt verwacht.
Resultaten voor de G-statistiek (GFIT) en het overeenkomstig significantieniveau (PFIT) en de gestandaardizeerde G-statistiek (ZFIT) tonen dat de fits gemiddeld gezien juist gebeuren. In het bijzonder ZFIT zou in principe dienen overeen te komen met een standaardnormaal verdeling (zie PLOT ZFIT). Dit is niet helemaal het geval omdat voor kleine ZFIT waarden het algoritme de drempelwaarde automatisch verhoogt om een betere fit te bekomen.
Tenslotte wordt de maximale fout getoond bij de ML-schatting van k en dit voor alle schattingen die in het algoritme worden uitgevoerd (alle bootstraps en schattingen op de originele verdeling). De nauwkeurigheid die wordt bereikt is in 98% van de gevallen bijzonder hoog (zie PLOT KERRMAX). In enkele gevallen blijkt het algoritme minder goed te convergeren (de iteratie voor de ML-waarde van k wordt stopgezet na 50 stappen). De nauwkeurigheid is echter nog steeds meer dan aanvaardbaar indien men deze fout vergelijkt met de standaardfout van k.
5.2. Gesimuleerde WEIBULL verdeling met duplicaten
Detailresultaten voor deze simulatie worden getoond in Appendix C. We bespreken hier voornamelijk de afwijkingen ten opzichte van het vorige geval.
Deze simulatie is een voorbeeld van een extreme correlatie. Eerder dan 1500 meetpunten zijn in feite slechts 300 onafhankelijke meetpunten aanwezig.
De samenvattende statistieken in Appendix C tonen dat dit goed wordt gedetecteerd door het algoritme. In alle gevallen wordt de steekproefomvang vermindert. Het gemiddelde komt overeen met 392 hetgeen hoger is dan het juiste aantal 300. Dit is echter te verwachten omdat in het algoritme een 90% boven-betrouwbaarheidsgrens wordt gebruikt voor de equivalente steekproefomvang. PLOT NEQV toont dat de 10% benedenkwantiel van NEQV inderdaad dicht bij de waarde 300 ligt.
Het algoritme blijkt in dit opzicht dus goed te werken. De variatie van NEQV is opnieuw ongewenst en zou verminderd kunnen worden door het opvoeren van het aantal bootstrap. De relatieve spreiding van NEQV is ongeveer 30%. De fout bij de schatting van de standaardfout varieert echter met de vierkantswortel van NEQV en men mag dus een nauwkeurigheid van ongeveer 15% verwachten bij de schatting van de standaardfout.
De resultaten voor u en k tonen dat de fout voor de schatting eerder 20 tot 30% bedraagt. Dit is te verwachten vermits naast de foute schatting van NEQV ook de bootstrap zelf een fout genereert op de schatting van de standaardfout.
De schatting van de standaardfouten is in ieder geval merkelijk beter dan het geval waarbij geen rekening wordt gehouden (zie SMLU0 en SMLK0). In dit geval worden de resultaten systematisch als meer nauwkeurig beoordeeld dan in werkelijkheid het geval is.
De overige resultaten zijn gelijkaardig aan de vorige gevallen. Bij de schatting van u en k wordt wel één enkele uitbijter genoteerd (zie PLOT EMLUEMLK ) hetgeen vermoedelijk te wijten is aan een toevallige maar extreme afwijking van de vooropgestelde Weibull verdeling.
5.3. Gesimuleerde lognormaal-WEIBULL verdeling
Resultaten van deze simulatie worden getoond in Appendix D.
Gemiddeld over de 200 simulaties is de drempelwaarde 81.9 hetgeen de theoretische waarde van 80 dicht benadered. De variatie van simulatie tot simulatie is redelijk groot (van 45 tot 170) maar vermits de lognormaalverdeling de Weibull dicht benaderd in dit gebied is dit niet verwonderlijk.
De schatting van de Weibull verdeling zonder de gegevens beneden de drempelwaarde te verwijderen leidt duidelijk tot foute resultaten (zie MLU0, MLK0, SMLU0 en SMLK0) die bovendien als te nauwkeurig worden geschat. Met de automatische schatting van de drempelwaarde wordt gemiddeld gezien de juiste waarde gevonden. De standaardfout van deze schatters is echter hoger zoals men zou mogen verwachten. De geschatte standaardfout is gemiddeld gezien iets lager dan de standaarddeviatie die men vindt bij de 200 simulaties. Dit is te wijten aan het feit dat in het eerste geval de drempelwaarde gekend wordt verondersteld, terwijl in de simulaties de drempelwaarde varieert van geval tot geval hetgeen tot een bijkomende spreiding aanleiding geeft.
Het significantieniveau (PFIT) is gemiddeld gezien iets te laag (t.o.v. de waarde 0.5). Dit is echter te verwachten vermits het algoritme naar de beste fit zoekt (d.w.z. met de kleinste MSE van de G-statistiek) maar, wanneer het significantieniveau groter is dan 0.5, de drempelwaarde niet verder verhoogt.
6. TOEPASSING OP WERKELIJKE GEGEVENS
In dit hoofdstuk bespreken hoe de blokomvang en de tijdscategoriën zijn vastgelegd voor de uiteindelijke toepassing van het schattingsalgoritme op werkelijke gegevens.Tenslotte worden de resultaten voor de niet-directionele metingen ter plaatse van A2-boei bondig besproken.
6.1. Keuze van de Blokomvang
Om de niet-parametrische bootstrapping uit te voeren die deel uitmaakt van het algoritme moeten de gegevens gebundeld worden in verschillende tijdsblokken.Concreet gebeurt dit als volgt: er wordt vooropgesteld om M opeenvolgende metingen in 1 blok te plaatsen.Het totaal aantal gegevens N is echter niet noodzakelijkerwijze een veelvoud van M, zodat het laatste blok een beperkt aantal gegevens M’=N-M*integer(N/M) kan bevatten. Om te vermijden dat M’ te sterk zou afwijken van het vooropgestelde aantal, wordt daarom voor alle gehele waarden K tussen 0.9M en 1.1M de verhouding van M’/K onderzocht en wordt die waarde van K als blokomvang gekozen waarvoor deze waarde maximaal is.
Om na te gaan wat een goede keuze is voor de waarde van M, werd de schattingsprocedure meermaals (7x) uitgevoerd voor waarden van M=100, 300 en 500.De gegevens die hierbij werden gebruikt betreffen de directionele HS metingen ter plaatse van Westhinder. Deze metingen betreffen de periode 1990 tot en met 1998 en omvatten 92338 waarden.Volgende tabel toont de resultaten van deze analyse:
|
M |
RUN | NEQV | HTRE | EMLU | SMLU | EMLK | SMLK |
| 100 | gemiddelde | 2021 | 91 | 108.4 | 2.02 | 1.42 | 0.036 |
| standaard deviatie | 457 | 9 | 0.6 | 0.18 | 0.01 | 0.005 | |
| 1 | 2310 | 95 | 108.2 | 1.94 | 1.42 | 0.034 | |
| 2 | 2230 | 95 | 108.2 | 1.91 | 1.42 | 0.029 | |
| 3 | 1552 | 75 | 109.7 | 2.03 | 1.45 | 0.041 | |
| 4 | 1881 | 95 | 108.2 | 2.05 | 1.42 | 0.035 | |
| 5 | 2764 | 100 | 107.8 | 1.81 | 1.41 | 0.032 | |
| 6 | 1447 | 85 | 108.8 | 2.39 | 1.43 | 0.043 | |
| 7 | 1966 | 95 | 108.2 | 2.01 | 1.42 | 0.036 | |
| 300 | gemiddelde | 1180 | 68 | 110.4 | 2.48 | 1.47 | 0.042 |
| standaard deviatie | 310 | 5 | 0.5 | 0.36 | 0.01 | 0.004 | |
| 1 | 1678 | 75 | 109.7 | 1.95 | 1.45 | 0.036 | |
| 2 | 753 | 65 | 110.6 | 3.07 | 1.48 | 0.049 | |
| 3 | 1144 | 65 | 110.6 | 2.38 | 1.48 | 0.042 | |
| 4 | 991 | 65 | 110.6 | 2.42 | 1.48 | 0.044 | |
| 5 | 1402 | 75 | 109.7 | 2.23 | 1.45 | 0.040 | |
| 6 | 979 | 65 | 110.6 | 2.77 | 1.48 | 0.041 | |
| 7 | 1315 | 65 | 110.6 | 2.54 | 1.48 | 0.040 | |
| 500 | gemiddelde | 1058 | 66 | 110.3 | 2.53 | 1.48 | 0.043 |
| standaard deviatie | 169 | 4 | 0.3 | 0.23 | 0.01 | 0.003 | |
| 1 | 817 | 65 | 110.5 | 2.83 | 1.49 | 0.043 | |
| 2 | 1264 | 65 | 110.5 | 2.11 | 1.49 | 0.040 | |
| 3 | 891 | 65 | 110.5 | 2.68 | 1.49 | 0.041 | |
| 4 | 1212 | 65 | 110.5 | 2.40 | 1.49 | 0.042 | |
| 5 | 1084 | 75 | 109.5 | 2.63 | 1.46 | 0.047 | |
| 6 | 972 | 65 | 110.5 | 2.56 | 1.49 | 0.048 | |
| 7 | 1166 | 65 | 110.5 | 2.46 | 1.49 | 0.043 |
De variatie van de schattingsresultaten voor dezelfde waarde van M is het gevolg van het gebruik van de bootstrapping.Omdat het toeval een rol speelt bij deze "resampling" techniek (blokken worden lukraak gekozen) en omdat een beperkt aantal bootstraps worden uitgevoerd (100 niet-parametrische bootstraps en 200 parameterische bootstraps) is een beperkte variatie van de schattingen te verwachten.Uit de resultaten blijkt dat deze variatie echter beperkt is ten overstaan van de geschatte standaardfout van de schattingen.Bijvoobeeld voor M=100, is de variatie van de schatting u gelijk aan 0.6 ten overstaan van een gemiddelde schatting van de standaardfout van 2.02.Voor een grotere blokomvang vermindert deze variatie nog verder en is het algoritme meer stabiel.
Wanneer de blokomvang te klein is (d.w.z. wanneer de gegevens in de verschillende blokken nog sterk gecorreleerd zijn) dan mag men verwachten dat de spreiding van de resultaten bij de niet-parametrische bootstrap wordt onderschat en de equivalente steekproefomvang wordt overschat.Dit blijkt zeer duidelijk uit voorgaande runs.Voor M=100 vindt men een gemiddelde equivalente steekproefomvang van 2021 gegevens, terwijl men voor M=300 en M=500 respectievelijk 1180 en 1058 vindt.Het blijkt dus dat een blokomvang tussen 300 en 500 tot stabiele resultaten leidt.Voor verdere analyses wordt daarom M gelijkgesteld aan 500 hetgeen tot de kleinste variatie leidt van de schattingen.
6.2. Keuze van de Tijdscategoriën
Wanneer men de tijdscategorie gelijkstelt aan maandelijkse perioden, dan werd opgemerkt bij de toepassing van het algoritme dat in sommige gevallen relatief hoge correcties dienen te worden uitgevoerd om een uniforme verdeling van de steekproefomvang te bekomen over de verschillende maanden.Dit is zo, omdat bij de niet-parametrische bootstrap de tijdsblokken lukraak worden gekozen en, indien slechts reeds voor de originele gegevens een beperkt aantal blokken aanwezig zijn in een tijdscategorie, dan kan het gebeuren dat voor die tijdscategorie in één van de bootstrapruns het aantal blokkenzeer laag wordt.
Om dit te vermijden wordt voor de finale toepassing van het algoritme voorgesteld om driemaandelijkse tijdscategoriën te gebruiken (januari-maart, april-juni, juli-september, october-december).Bij de maandelijkse runs werd overigens opgemerkt dat systematisch tijdens de wintermaanden relatief minder gegevens aanwezig zijn in de originele gegevens.Dit is ook logisch vermits tijdens deze maanden de zeetoestand en de climatologische omstandigheden meer extreem zijn en het uitvallen van het meetinstrument zich meer frequent voordoet.
Wanneer het algoritme toch wordt toegepast op basis
van maandelijkse tijdscategoriën dan worden maanden waarvoor het aantal
blokken te klein zijn automatisch samengevoegd.Voor
tijdscategoriën van een benaderend zelfde tijdsduur, zou het aantal
blokken per tijdscategorie ideaal hetzelfde dienen te zijn en gelijk aan
MT=N/(M*NT) waarbij N het totaal aantal gegevens voorstelt, M overeenkomt
met de blokomvang en NT het aantal tijdscategoriën voorstelt.Omdat
de eventuele correctiefactor voor de steekproefomvang beperkt wordt tot
een factor 3, wordt als regel gebruikt dat het aantal blokken in elke tijdscategorie
minstens gelijk dient te zijn aan MT/3+1.5 ![]() .De
laatste factor 1.5
.De
laatste factor 1.5 ![]() wordt toegevoegd om rekening te houden met toevallige afwijkingen van het
blokaantal in een tijdscategorie ten gevolge van de lukrake selectie.Wanneer
een tijdscategorie niet aan deze voorwaarde voldoet dan wordt de tijdscategorie
samengevoegd met de volgende tijdscategorie.
wordt toegevoegd om rekening te houden met toevallige afwijkingen van het
blokaantal in een tijdscategorie ten gevolge van de lukrake selectie.Wanneer
een tijdscategorie niet aan deze voorwaarde voldoet dan wordt de tijdscategorie
samengevoegd met de volgende tijdscategorie.
6.3. Resultaten van de toepassing van het algoritme voor de H33 metingen ter plaatse van A2-boei
Het schattingsalgoritme, gebruik makend van voorgaande parameter waarden, is toegepast op de H33 metingen ter plaatse van A2-boei.Om na te gaan of de betrouwbaarheidsintervallen effectief de variatie van de schattingen weergeven, is het algoritme meermaals toegepast terwijl steeds meer metingen in rekeningen worden gebracht.Hiertoe zijn vanaf 1981 opeenvolgende 3-jaarlijkse periodes beschouwd: deeerste run komt dan overeen met de periode 1981 tot en met 1983, de tweede run met de periode 1981 tot en met 1986, etcetera.In totaal zijn er aldus 6 runs uitgevoerd.Tenslotte is een finale run uitgevoerd die alle gegevens gebruikt (de eerste metingen dateren van 1977 maar zijn zeer incompleet) en, opnieuw voor alle gegevens, zijn analyses uitgevoerd voor de metingen in ieder kwartaal.
De volgende tabel vat de resultaten van deze runs
samen.Hieruit blijkt dat in run
1 (gegevens van 1981 tot en met 1983) de gegevens zeer onvolledig zijn
in het eerste kwartaal.Omdat de
correctiefactor beperkt is tot 3, wordt slechts een gedeeltelijke aanpassing
gemaakt.Als gevolg hiervan is het
resultaat vertekend.Het equivalent
aantal meetpunten is eveneens zeer laag (slechts 80 meetpunten) en, voor
zulk een lage steekproefomvang, wordt de drempelwaarde van 0 aanvaard.Verdere
runs stabiliseren zich vrij snel en convergeren naar een drempelwaarde
van 90 cm.De u-parameter convergeert
naar 75 cm, terwijl een waarde van 1.38 wordt geschat voor de k-parameter.Wanneer
alle metingen worden gebruikt (ook deze voor 1981) dan verhoogt de u-waarde
licht, terwijl de k-parameter praktisch ongewijzigd blijven.De
analyse van de metingen in de verschillende kwartalen tonen significante
verschillen in de parameters.
|
Schatting
van de Weibull verdeling
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|